所谓线性注意力,是指所需内存空间随着序列长度成线性增长的注意力机制,实现它的模型有mamba等选择性状态空间模型。
所谓平方注意力,是指所需内存空间随着序列长度的平方增长的注意力机制,实现它的模型就是最典型的transformer。
我在想:线性注意力的特征是把所有上文有关的历史内容压缩到一个固定长度的状态之中,这类似于人类日常会话的“我想说什么”状态就直接形成语言说出来了。平方注意力的特征是要把所有的上下文词元的相互关系都注意到,也就是说会检查上下文的关系,这有点类似于人类写论文,总要时不时停下来检查上下文之间重要内容的相互关系。
这里还有一个线性注意力的例子。你饿了,想吃炸鸡;这个时候你是脱口而出“我饿了,想要吃炸鸡”,作用起来一定是心里有一个写进状态的意愿“饿/要吃+炸鸡”,然后从“我”字开始,一个一个的迅速连缀成一句话。这时候老妈听见了,可能不下意识地针对这句话就直接响应回答说:哦好呀,咱家今天中午吃炸鸡。我觉得这就是线性注意力的表现。
而对于平方注意力,那就是进行书面写作的时候考虑上下文的关系,例如(英文)先写了时间Yesterday,心里想要表达的意思是“昨天+吃+炸鸡”,写句子的时候,I 后面跟的eat就要变成ate或者是have eaten;当然这是一个贴近中文母语学英文的人的思维例子,不过书面写长而且语法句法关系复杂的句子,都是这一类。长句举例:因为季风从沿海向内陆扩展的分布,由于生产生活方式的不同,中原文明与北方游牧民族的分布范围在山脉与草原的边界上形成了一条自然边界线——中原文明建造的长城,也即牧马人口中的“长白墙”就在那里建成。这个长句我写出来的时候至少进行了三次修改,每一次都涉及一对前后文名词之间的关系(中原文明/北方游牧民族→自然边界,山脉与草原→季风,分布范围/自然边界线→长城),这就是平方注意力检查前后文的做法;此外,互文手法恐怕也是平方注意力的例子。
人类应该同时具有线性注意力和平方注意力的模式。关于线性注意力与平方注意力在人类思维方式上的体现,有一个重要的问题就是何者为原生何者为次生的关系。这个问题留给大家思考。
更进一步地,我在思考是否有什么样的方式,能够在一种AI模型上统一线性注意力和平方注意力。这不是简单的混合,而是要有效率的组合。但目前还是没有想到这种统一两种注意力的模型该实现什么样的工程目标(就是说啥样才能叫做“最有效率”),其次也想不到该如何将其统一起来。
最后留一个思考的问题:某中学校长给大家讲话:“同学们,我今天要讲三个主题”(伸出四个手指),讲完第三个主题之后,他发现自己想讲第四个,但是稿子上没有,于是打了个哏儿,迟疑了几秒钟,然后接着讲他即兴(或许也不是完全即兴)想出来的第四个问题。你觉得这位校长体现的是线性注意力呢,还是平方注意力呢?
1 个赞
感觉按照你提供的定义,即兴的部分属于线性注意力,非即兴的部分属于平方注意力
按照空间复杂度的计算方法,我们应该将其归到平方注意力里。
lsamc
2026 年4 月 7 日 12:25
3
楼主的帖子非常启发思考!
这个问题是指: ‘人类的这两种注意力模式孰为主次’吗?
混合注意力这个点子很有意思, 但是我只能简单地想到routing这一种’简单的’方式–毕竟人类(我猜)也是有的话线性注意力(如流水账? 想到哪里说到哪里), 有的话仔细思考(有意思的是,人类上下文还短的很,没有特殊训练的话context可能都不够小数除法甚至是百位乘法…). 因此我觉得路由比较符合直觉, 楼主这个idea很有意思, 我也有空做点实验试试看
最后的问题, 是不是线性? 因为前面其实也是对着稿子念的,没啥前后思考对照. 但是看起来说想讲3/4点的时候潜意识发力了所以手势比了4(虽然嘴上还是念得稿子), 最后确实来讲第四点了(也就是潜意识是想讲第四点的), 属于是没有仔细前后思考? 而且后面吱哇的话也不用很仔细的和前面对照, 虽然"注意到了"前面手势是4,但是也可能只是校长脑袋里状态压缩了"我要讲4条"
这么说,也许人脑其实只有线性注意力,前面的"平方上下文"其实都是靠久经锻炼的人脑状态压缩提供的幻觉? 或者其实context很小的平方注意力可以被精心设计,训练的(比方说生活了18年的)线性注意力替代?
其实非即兴的部分属于照本宣科,对着稿子念
我倒是在想,这位校长先生打哏儿吱哇的时候,应该是出现了一个平方注意力的:他在搜索“第四条”与前面三条的关系,然后过渡说“除了以上三部分ABC,我还要补充一点D”。但这个过程同时涉及脑海里的隐状态“第四条”和文本上的前文(特别是注意力汇集的总结性和结构性的部分)。
1 个赞
有时候名字这种东西真的很奇妙,你看mamba好像是一种蛇,但这种架构在某方面真的就像蛇一样连成顺序的一串而不是展成一个方阵。
我其实有点担心我对线性注意力和平方注意力的描述过分简化或有不当之处。但总之我是说出了在数学实现之外的我所理解的核心特征,即一个不能全面地检查上下文词语的相关之处,另一个则是要检查上下文词语的相关之处。
我提到的人类的两种注意力模式的原生和次生问题,本身的含义是:在未经书面写作教育之前的人类(从生物学的角度可以理解为纯粹野生的人),究竟是神经系统先发展出了线性注意力,还是平方注意力?换言之,是否线性注意力是人类这种生物自带的原生的,而平方注意力是通过教育等习得的?
还可以换一个角度,从进化论的角度上看:线性注意力是从进化树中原生出现吗?而平方注意力则未出现在进化树中(后天习得)或者是出现得很晚(晚于智人的出现时间)。
至于主次,我觉得日常生活中一定是线性注意力为主…因为日常会话很短,不需要平方注意力——况且谁又会天天检索自己说过的上一句呢?除非是犯了错被老师和父母叫去训话。平方注意力的能量开销应该远大于线性注意力。
关于校长讲话这个例子,我在想,或许就是吱哇的那一声和后面的那一句启动了平方注意力,因为他要检索上文发现稿子里确实没有第四点,然后需要构造一个衔接用的过渡句过渡到他要讲的第四点上(例如,除了以上讲的三点ABC,我还要补充一点,是啥啥啥)。
对于混合注意力和人脑是不是只有线性注意力的问题,这个确实很值得进一步思考。
对于混合注意力、人脑是不是只有线性注意力、context很小的平方注意力可以被精心设计的问题,我是这样想的:
1、对于混合注意力方面,你想到routing这种方式,deepseek 也想到了这种方式,但是从它的阐述中,我觉得这是一个两个模块组合的工程问题,而不是将模块混合的机制/架构问题。我觉得路由这种方式有着工程价值,可能是一个节省性能的方法。但是更进一步,我在想是否可能从理论上统一两种注意力,将其至于一个可以自动无缝切换的模型之下。
2、人脑是不是只有线性注意力这个问题我觉得很难讲。我更倾向于认为二者是兼有的,但是底层机制不同,而以前者为主(更节省能量)。这就扯到了哪个是原生哪个是次生的问题。当然在这之前,严格的学术论证,需要进行一系列认知心理学的实验来确定人类到底是不是只存在线性注意力。因为平方注意力在上下文不太大的时候是可以被模拟的。
3、之前说到平方注意力可以被模拟,我认为可以有两种机制:
a). 对生物,可以有大量已经被存储在头脑记忆里的“通用知识”键值对,例如“二次函数”对“抛物线”,“李白”对“唐诗”等等,这样就可以模拟约简后的平方注意力之中高权重的相关词语——这等于不是在上下文之中而是在预先形成的通用知识库里。
b). 我认为对于ai,模拟平方注意力的机制可以通过关键词衔接的查询函数查询上文,返回关联程度;例如,AI说到一个词“魏尔斯特拉斯椭圆函数”,上文有“椭圆曲线”和“雅可比椭圆函数”,即使它是线性注意力的,也完全可以在一个生僻词“魏尔斯特拉斯椭圆函数”后衔接查询函数,亦即”魏尔斯特拉斯椭圆函数+<?>+Context_Query+…+椭圆曲线,雅可比椭圆函数”。甚至人类的打哏儿,“嗯,我想想”“It’s like…like, yeah it’s like”,说不定都是类似的机制(查找上下文或者记忆库)。
补充一点,我觉得人类的上下文跟通用知识记忆库应该放在不同存储位置的。
1 个赞
lsamc
2026 年4 月 7 日 15:43
8
同意, 这个似乎是已经被证实了的. 就是失忆一般不会忘’知识’之类的
lsamc
2026 年4 月 7 日 15:45
9
另外, 你说的’架构上无缝混合的注意力模式听起来确实优雅, 但是我也实在没想到该是什么样. 先不说架构设计上该是什么样, 就单从表现上它是如何混合的呢?从表现上是一种路由吗?也许先从外层表现上开始明确需求,再来确定/启发内部架构实现比较好
qzero
2026 年4 月 8 日 01:42
10
感觉可以用模型权重来表示线性注意力?比如用lora来做TTT得到的那个参数矩阵,这个参数矩阵一定程度上可以认为是对最近一些对话的压缩。
不过这种方案有个问题,那就是loss到底是怎么来的?也就是用什么信号来驱动线性注意力改变,这个可能需要结合人脑的真实工作机制来设计了。
lsamc
2026 年4 月 8 日 05:34
11
TTT来说, 主要是两种方案: 一种是从环境反馈中直接获得监督信号; 另一种是根据熵,分布对齐等手段从输出中找置信度
回复你说的“想不到架构上无缝混合的注意力模式的样子”——我花了很长时间,但的确也想不出来是什么样子,大概需要一种完全不同于RNN或transformer的架构。不过,如果把“注意力”当成对记忆的权重检索能力,那么可以对RNN外插一种记忆模块来处理问题;最近查到的资料里提到Google Research 最新提出的 Memory Caching(MC),通过分段缓存中间状态向量,可以令整个系统具备从线性到平方之间的各自计算复杂度,或许这也是一个思路。
1 个赞
lsamc
2026 年5 月 24 日 01:21
14
其实本楼最近给我了一个大启发,因此我最近在尝试一件事情…
1 个赞
qzero
2026 年5 月 30 日 05:18
16
突然想到,之前看一个AI博主说过,DeepSeek V4的注意力机制和这个有点像,就是在普通的平方级别复杂度的Attention的基础上混合一些通过压缩得到的“线性注意力”,以此来实现1M的长上下文的稳定性。
就有点类似于人在看书的时候会大致记住书中的内容,但是不会准确记住每一个字,这个“大致印象”就是线性注意力部分,在需要做和书中某部分相关的问答时,能够根据这些“大致印象“翻书找到对应位置,然后作答。
不过还没有很具体的读过DeepSeek V4的技术报告,暂时还不是很确定这个结论,后面有机会研究一下
1 个赞
qzero
2026 年6 月 1 日 06:59
17
抽空研究了一波deepseek v4的注意力机制,好像还是平方级别增长的,只是说可以通过把多个token压缩为一个来节省attention计算开销,和线性完全不沾边
1 个赞
lsamc
2026 年6 月 2 日 02:41
18
qzero:
多个token压缩为一个
多个token压缩为一个是怎么搞的啊,你看懂了吗能省流一下吗(x
qzero
2026 年6 月 2 日 03:07
19
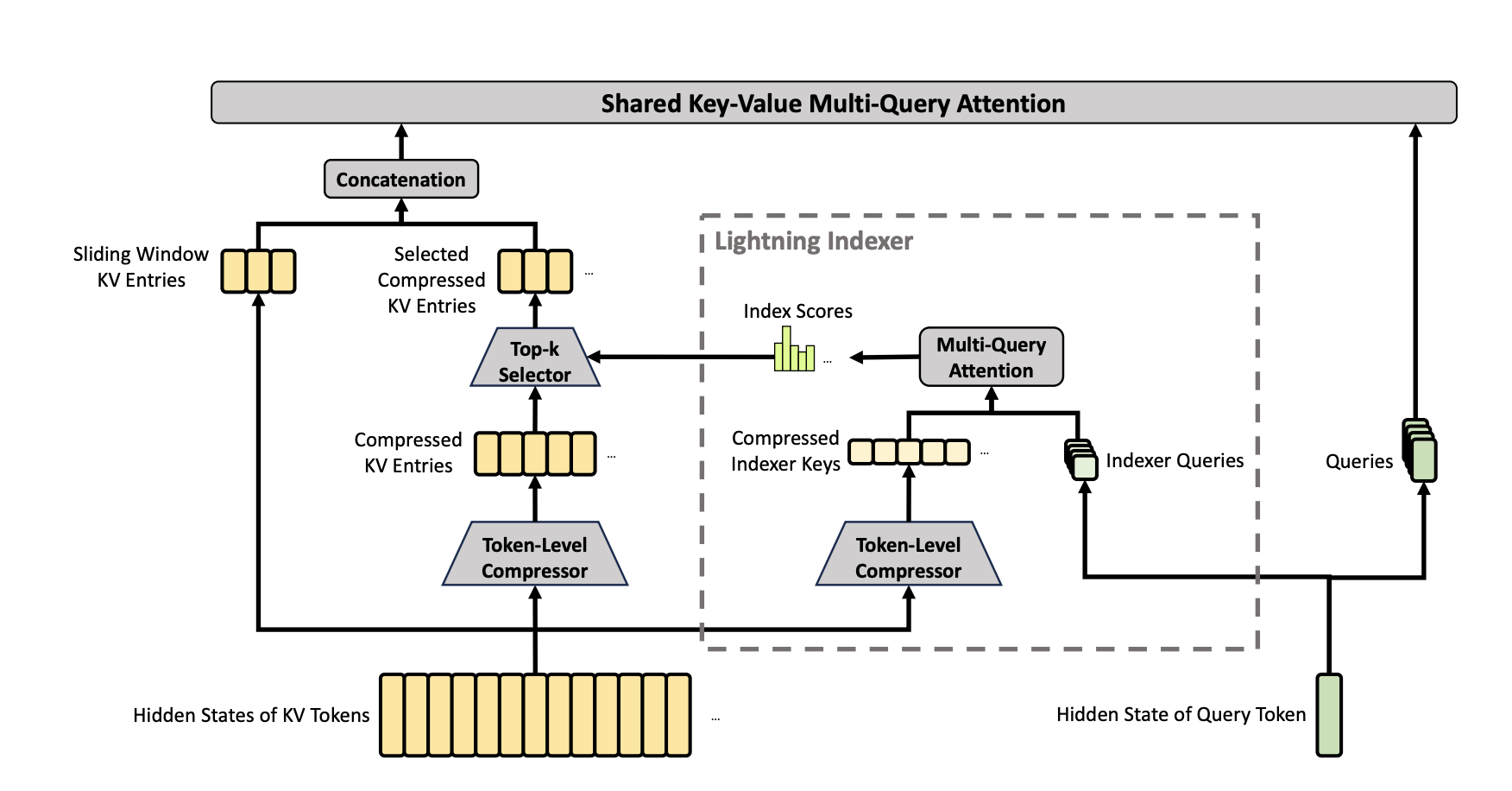
比如对于token:[1,2,3,4,5,6],首先经过QKV映射得到QKV
然后把K和V分组,比如把K分成:[[1,2], [3,4], [5,6]]
然后每一组过一个线性层,得到[K12, K34, K56],V同理,得到[V12, V34, V56]
然后用这个去和[Q1, Q2, Q3, Q4, Q5, Q6]做Multi-Query Atttention
(实际好像还会算一个score,从[K12, K34, K56]里面只选择其中的Top-K用来实际做Attention,所以实际参与计算的KV数量应该是比分组数量还要少的)
1 个赞