接1楼。这里画一些结构图,用以阐述选择性SSM与预测编码结合架构。
一如之前所示,这个架构是以选择性SSM作为预测编码的表征神经元(记作Chr. SSSM),再加上预测编码典型的误差神经元(记作Err. Neuron)构成的。我不同版本的代码有着不同的结合方式,但是它们一般说来可以用这样的形式来统一:
(y_{t}, h_{t})=SSSM(h_{t-1}, x_{t}, e)
它们的组合方式区别有:1. 误差e的处理方式,例如在SSSM内部是采用了简单加在 x_{t} 上还是参与了选择性的调制(我目前做的几个版本都是 x_{t}’=x_{t}+e_{t} ,除了代码还没修改完成的最新版);2. 上标区别,也就是层连接的区别,具体体现为SSSM之中的e究竟是对于h的本层( h^{l}, e^{l} )还是高一层( h^{l}, e^{l+1} )(我目前做的几个版本都是高一层)。
以下结合结构图进行阐述。
版本1&2:mamba块+PC/双线性系统近似+PC。
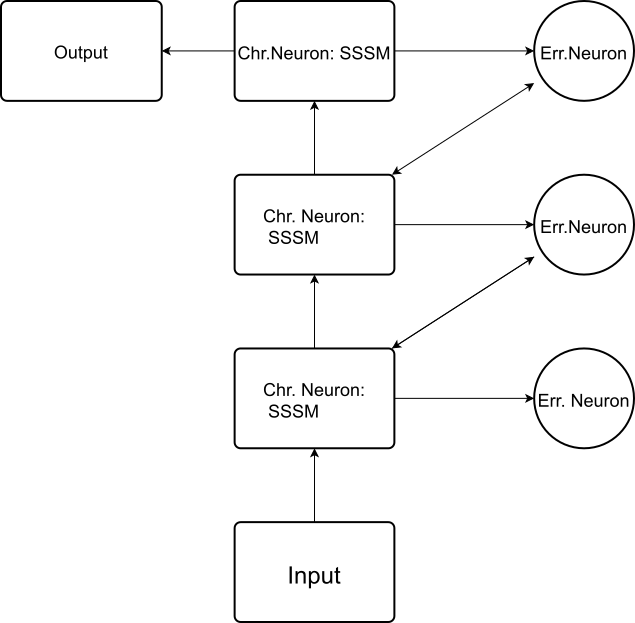
它们的结构如下图所示:
可以看出它们遵循的模式是以方框表示的表征神经元之间存在信息的直接逐层流动(这和传统的预测编码不同),而以圆圈表示的误差神经元之间不存在信息的直接流动(和经典预测编码相同)。任何一个误差神经元想要把自己的信息传递给高一层的误差神经元,则先要把信息传递给低一层的表征神经元,由低一层的表征神经元把信息传递给同层表征神经元,再传递给高一层的误差神经元。
这种架构的特征是把误差神经元当作了数值上小的校正,用以减缓异常或高变化数据引起的对表征神经元带来的冲击;误差神经元相当于表征神经元的副手,不能独立构造信号通路。同时,这种架构也完全不能带来传统预测编码所带来的逐层上升的数据抽象化——网络高层拿到的不是数据的抽象特征而是逐层被修饰和修改过的数据。站在语言模型的角度我们很容易理解这个构造:因为从输入端传到输出端的永远是语义空间之中的内容,不然就不能保证输出的内容是词汇。如果执行经典的预测编码构造,输出端输出的是某种特征——这更像是把句子的语气、情感之类的特征分了类——这样是不能胜任应答的语言任务的。但是,当我们把误差神经元的作用弱化为表征神经元副手的时候,实际上带来的效应就是表征神经元在干活,表征神经元起了最主要的作用;这一点可以从训练数据中误差编码的loss约为表征神经元loss的1%-0.1%观察到。
其余可以批评的内容,在于每层的误差神经元连接的方式。可以观察到,因为高一层的误差神经元调整本层的表征神经元,带来的问题是最低层的误差神经元不修饰任何事物;而且除了这个最低层的误差神经元以外,如果将每一个高层的误差神经元都下移一层到本层,其实得到的网络和原来的等效——就只是删去了一个最低层不干任何事情的误差神经元而已。
此外,我还要自我批评一下版本1(mamba+pc)和2(Bilinear+PC)中的误差放入SSSM的算法问题。如下图所示,它们只是参与了对每一层的输入数值的修正,而从未对选择性机制构成独立而主要的影响。
可以看得出,误差e是通过加在输入x上来影响SSSM的状态选择性的;而无论是mamba的状态选择性还是Bilinear近似的状态选择性,都是完全通过输入x来决定的。但因为e通常是个小值,所以对状态选择性的调制能力十分有限。【注:之前1楼的公式里,误差W*e是加在 h^{l} 层的输出之后的,但这样其实就相当于把 h^{l+1} 的输入数值加入了W*e】。
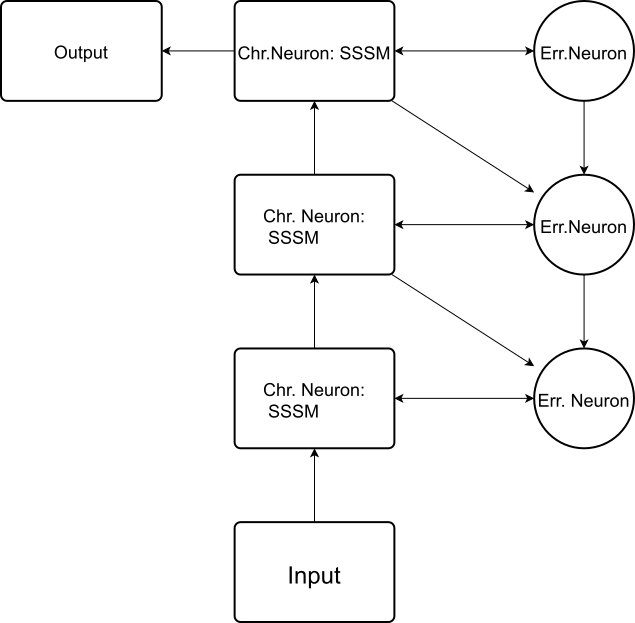
如果日后要在版本1和2的框架下加以微小的改进,我想或许是把误差神经元在每层的位置调整一下,也就是把原本高一层的误差神经元放在下面。如下图所示:
接下来是说版本3:版本3的代码目前还没有写完,确切的说写完了,但是必须通过优化才能跑。版本3已经完全抛弃了mamba架构,在双线性的基础上走的更远(注意之前的bilinear其实不是完全的bilinear,这不是由非线性激活函数造成而是由x*Wx项造成)。之前的版本2是把mamba里的exp(Δ*A)矩阵指数拆掉了(变成一阶近似),导致的结果就是必须加上layernorm防止数值失稳爆掉。版本3则引入了一个正规化标量因子f(r)=1/(1+r),除去内部状态的模长来防止数值爆炸,同时也是一种遗忘机制。之所以它在双线性上走的更远,是因为它对输入x和高一层的误差e,这两个变量对内部状态h都是双线性的;这样的设定针对的是之前误差e不调制状态选择性的问题。版本3还引进了误差神经元之间的信号通路,亦即:高一层误差神经元直接传递信息到本层误差神经元,用于调制f_pred()对本层神经元的操作。
如图所示:
这份架构实现了两条信息通路,即表征神经元向上的信息传递和误差神经元向下的信息传递。这种架构的要点在于不能容许信息未经调制的直接传递——也就是说不能容许残差神经元的形式,不能有直接加的x——它必须保证每一层的信息都充分地与其他信息发生了作用。
版本3的代码还未经测试。事实上问题不在架构而在代码实现。由于完全双线性要引入12个N*N的矩阵,这些矩阵在PyTorch的自动微分作用之下每一个时间步都会被保存下来,导致的问题是即使对序列长T=1024的训练数据,对于512维模型,其占用内存都会超过40GB. 因此必须重写forward里的算子来避免保存大的矩阵。512维模型已经是我能接受的最小的维数了。因此做下去就必须解决这个问题。
至于架构方面未来该如何改良,我想或许也就是把最底层的孤立误差神经元去掉,然后所有的高层误差神经元下移一层。如图所示:
如果更进一步对架构进行改良,就会是将误差神经元拆成抑制神经元和兴奋神经元两部分;那会是更加复杂但也可能是更加仿生的构造。
不过不管怎么说,这一类实现了信息上行和指导下行的神经网络结构,都有在输出端之后加入决策器的构造可能。那样或许可以应用到一类更广阔的事物之上。
附:版本1(mamba-pc)模型代码
%%writefile models.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class SSSM(nn.Module):
"""
本模块负责核心的状态空间演进,不包含外部的卷积和门控。
"""
def __init__(self, d_model, d_state):
super().__init__()
self.d_model, self.d_state = d_model, d_state
# 初始化 A 矩阵
A = torch.arange(1, d_state + 1).repeat(d_model, 1).float()
self.A_log = nn.Parameter(torch.log(A))
self.D = nn.Parameter(torch.ones(d_model))
# 选择性机制:生成 dt, B, C
self.x_proj = nn.Linear(d_model, d_state * 2 + 1, bias=False)
self.dt_proj = nn.Linear(1, d_model)
nn.init.constant_(self.dt_proj.bias, -4.0)
# 输出线性层
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x, h_prev):
# x: (batch, d_model)
A = -torch.exp(self.A_log)
projected = self.x_proj(x)
dt_raw, B, C = torch.split(projected, [1, self.d_state, self.d_state], dim=-1)
# 离散化
dt = torch.clamp(F.softplus(self.dt_proj(dt_raw)), min=1e-4, max=0.1)
A_bar = torch.exp(dt.unsqueeze(-1) * A.unsqueeze(0))
B_bar = dt.unsqueeze(-1) * B.unsqueeze(1)
# 状态更新 (SSM 核心)
h_t = A_bar * h_prev + B_bar * x.unsqueeze(-1)
# 计算输出
y = torch.einsum('bds,bs->bd', h_t, C) + x * self.D
return self.out_proj(F.silu(y)), h_t
class SSPCLayer(nn.Module):
"""
重点:
1. 合并了输入投影 z_proj 和 x_proj 减小显存开销。
2. f_pred 为带 SiLU 激活的预测函数。
3. 集成了 1D 卷积。
"""
def __init__(self, dim, d_state, d_conv=4):
super().__init__()
self.dim = dim
# --- 显存优化:合并投影层 ---
# 原本是 z_proj(dim->dim) 和内部输入投影,现在统一合并为一个大层 (dim -> dim * 2)
# 一半用于 SSM 支路 (x),一半用于门控支路 (z)
self.merged_in_proj = nn.Linear(dim, dim * 2, bias=False)
# 局部卷积层 (Mamba 标配)
self.conv1d = nn.Conv1d(
in_channels=dim,
out_channels=dim,
kernel_size=d_conv,
groups=dim,
padding=d_conv - 1
)
# 实例化 SSSM
self.sssm = SSSM(dim, d_state)
# 预测函数 f_pred 为 Linear + SiLU
self.f_pred = nn.Sequential(
nn.Linear(dim, dim),
nn.SiLU()
)
self.down_weight = nn.Parameter(torch.full((1,), 0.05))
def forward(self, x_step, h_prev, z_step, e_top_prev=None):
"""
x_step: 当前时刻经过卷积处理后的 SSM 支路输入
z_step: 当前时刻的门控支路输入
e_top_prev: 来自高层的预测误差反馈
"""
# 融合预测编码的自上而下反馈:将误差修正引入 SSM 输入
ssm_input = x_step + self.down_weight * e_top_prev if e_top_prev is not None else x_step
# 进入核心 SSSM 单元
y, h_t = self.sssm(ssm_input, h_prev)
# 门控组合:y * SiLU(z) -> Mamba 的标志性结构
# 注意:z_step 已经在外部或传入前经过了初步处理
output = y * F.silu(z_step)
return output, h_t
class SSPCModel(nn.Module):
def __init__(self, vec_dim, model_dim, d_state, num_layers):
super().__init__()
self.model_dim, self.num_layers, self.d_state = model_dim, num_layers, d_state
self.input_proj = nn.Linear(vec_dim, model_dim)
self.layers = nn.ModuleList([SSPCLayer(model_dim, d_state) for _ in range(num_layers)])
self.output_head = nn.Linear(model_dim, vec_dim)
def forward(self, x_seq, states=None):
batch_size, seq_len, _ = x_seq.shape
device = x_seq.device
# 初始化 SSM 隐状态
if states is None:
states = [torch.zeros(batch_size, self.model_dim, self.d_state).to(device) for _ in range(self.num_layers)]
# 初始化预测误差
errors = [torch.zeros(batch_size, self.model_dim).to(device) for _ in range(self.num_layers + 1)]
# 初始词嵌入投影
x_emb = self.input_proj(x_seq)
all_vec_outputs, pc_loss_sum = [], 0
# --- 优化策略:在时间循环外预计算卷积和合并投影,以节省显存和加速 ---
# 注意:由于层级间的 SSPC 依赖,每一层的输入需要实时计算,
# 但我们可以在每一层内部对输入序列进行一次性卷积预处理。
current_layer_input = x_emb
for t in range(seq_len):
new_states, layer_outputs = [], []
for l in range(self.num_layers):
# 获取当前层的输入
h_in = current_layer_input[:, t] if l == 0 else layer_outputs[l-1]
# --- 使用 chunk 切分合并后的投影 ---
# 这一步将 h_in 一次性投射到 2*dim,然后切分为 SSM 支路和门控支路
combined = self.layers[l].merged_in_proj(h_in)
x_ssm_raw, z_gate = combined.chunk(2, dim=-1)
# 为了保持简单且适宜家用机,卷积可以在这里简化处理或作为状态维护
# 此处为了演示原理,假设卷积已通过某种方式作用于 x_ssm_raw
# 在实际针对序列的训练中,卷积通常在循环外对整个 x_ssm 序列预执行一次
# 调用更新逻辑 (应用了改名后的 sssm 和新 f_pred)
out_l, h_t_l = self.layers[l](x_ssm_raw, states[l], z_gate, errors[l+1])
new_states.append(h_t_l)
layer_outputs.append(out_l)
# 预测编码损失计算:使用升级后的带 SiLU 的 f_pred
step_pc_loss = 0
for l in range(self.num_layers - 1):
# 高层状态通过 f_pred (Linear + SiLU) 预测低层状态
h_pred = self.layers[l].f_pred(layer_outputs[l+1])
error = layer_outputs[l] - h_pred
errors[l] = error.detach()
step_pc_loss += torch.mean(error**2)
pc_loss_sum += step_pc_loss
states = new_states
# 【关键注释】:原本输出的是网络最底层(Layer 0)的表征神经元数值 all_layer0_outputs.append(layer_outputs[0])
# 【必须】改成输出网络最高层的表征神经元数值
all_layer0_outputs.append(layer_outputs[-1])
return torch.stack(all_vec_outputs, dim=1), states, pc_loss_sum / seq_len
# SSPCLanguageModel 保持不变,它会自动调用重命名后的核心组件
class SSPCLanguageModel(nn.Module):
def __init__(self, vocab_size, vec_dim, model_dim, d_state, num_layers):
super().__init__()
self.embedding = nn.Embedding(vocab_size, vec_dim)
self.sspc_core = SSPCModel(vec_dim, model_dim, d_state, num_layers)
self.lm_head = nn.Linear(vec_dim, vocab_size)
self.lm_head.weight = self.embedding.weight
def forward(self, input_ids, states=None):
x_vecs = self.embedding(input_ids)
# 【关键注释】:输出的是网络哪一层的表征神经元数值?
pred_vecs, next_states, pc_loss = self.sspc_core(x_vecs, states)
logits = self.lm_head(pred_vecs)
return logits, next_states, pc_loss
@torch.no_grad()
def generate(self, input_ids, max_new_tokens, temperature=1.0, top_k=50):
self.eval()
generated = input_ids
states = None
for _ in range(max_new_tokens):
logits, states, _ = self.forward(generated[:, -1:], states)
next_token_logits = logits[:, -1, :] / (temperature + 1e-8)
v, _ = torch.topk(next_token_logits, min(top_k, next_token_logits.size(-1)))
next_token_logits[next_token_logits < v[:, [-1]]] = -float('Inf')
probs = torch.softmax(next_token_logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
generated = torch.cat((generated, next_token), dim=1)
if next_token.item() == 3: break # [EOS]
return generated
附:版本2(双线性SSM-PC)代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SSSM_Bilinear(nn.Module):
"""
双线性mamba近似状态空间模型的核心实现
h_t = (A0 + delta_t * A_delta) h_{t-1} + (B0 + delta_t * B_delta) x_t
y_t = C0 * h_t + g_t * (C1 * h_t)
"""
def __init__(self, d_model):
super().__init__()
self.d_model = d_model
# 标量控制头:生成步长 delta 和 选择性门控 g
self.delta_head = nn.Linear(d_model, 1)
self.gate_head = nn.Linear(d_model, 1)
# 核心矩阵 A, B, C
self.A0 = nn.Parameter(torch.eye(d_model) * 0.9)
self.A_delta = nn.Parameter(torch.randn(d_model, d_model) * 0.001)
self.B0 = nn.Parameter(torch.randn(d_model, d_model) * 0.001)
self.B_delta = nn.Parameter(torch.randn(d_model, d_model) * 0.001)
self.C0 = nn.Parameter(torch.randn(d_model, d_model) * 0.001)
self.C1 = nn.Parameter(torch.randn(d_model, d_model) * 0.001)
# 增加一个内部归一化,防止状态 h_t 溢出
self.norm = nn.LayerNorm(d_model)
def forward(self, x_t, h_prev):
# 计算控制变量
# 钳定 delta_t,防止步长过大导致状态飞出
# 限制 delta 在 [1e-6, 1.0] 之间
delta_t = torch.clamp(F.softplus(self.delta_head(x_t)), min=1e-6, max=1.0)
g_t = torch.sigmoid(self.gate_head(x_t))
# 构造有效 A 和 B 矩阵
# A_eff: (batch, d_model, d_model)
A_eff = self.A0.unsqueeze(0) + delta_t.unsqueeze(-1) * self.A_delta.unsqueeze(0)
B_eff = self.B0.unsqueeze(0) + delta_t.unsqueeze(-1) * self.B_delta.unsqueeze(0)
# 状态更新
# 使用 tanh 限制状态更新的幅度,或者在更新后进行 norm
h_t = torch.bmm(A_eff, h_prev.unsqueeze(-1)).squeeze(-1)
h_t = h_t + torch.bmm(B_eff, x_t.unsqueeze(-1)).squeeze(-1)
# 这一步非常重要:防止递归过程中数值无限增长
h_t = self.norm(h_t)
# 输出计算(双线性门控输出)
y_t = h_t @ self.C0.T + g_t * (h_t @ self.C1.T)
return y_t, h_t
class SSPCLayer(nn.Module):
def __init__(self, dim, d_conv=4):
super().__init__()
self.dim = dim
# 保留一维卷积提取局部特征
self.conv1d = nn.Conv1d(dim, dim, kernel_size=d_conv, groups=dim, padding=d_conv - 1)
# 替换为双线性核心
self.sssm = SSSM_Bilinear(dim)
# 预测函数 f_pred
self.f_pred = nn.Sequential(nn.Linear(dim, dim), nn.SiLU())
# 误差反馈权重
self.down_weight = nn.Parameter(torch.full((1,), 0.01))
def forward(self, x_step, h_prev, e_top_prev=None):
# 融合自上而下的误差反馈
ssm_input = x_step + self.down_weight * e_top_prev if e_top_prev is not None else x_step
# 通过双线性核心
y, h_t = self.sssm(ssm_input, h_prev)
# 注意:此处移除了原 Mamba 的 z_gate 门控,因为 SSSM_Bilinear 内部已包含 g_t 门控
return y, h_t
class SSPCModel(nn.Module):
def __init__(self, model_dim, num_layers):
super().__init__()
self.model_dim = model_dim
self.num_layers = num_layers
# 构建层级
self.layers = nn.ModuleList([SSPCLayer(model_dim) for _ in range(num_layers)])
def forward(self, x_emb, states=None, top_error_noise=None):
batch_size, seq_len, _ = x_emb.shape
device = x_emb.device
# 初始化状态 (双线性版本状态维度为 [B, D])
if states is None:
states = [torch.zeros(batch_size, self.model_dim).to(device) for _ in range(self.num_layers)]
# 初始化预测误差
errors = [torch.zeros(batch_size, self.model_dim).to(device) for _ in range(self.num_layers + 1)]
# 如果传入了生物启发式噪声,将其注入到高于最高层的误差神经元中
if top_error_noise is not None:
errors[self.num_layers] = top_error_noise
# 序列一维卷积预处理
# 形状变换: (B, L, D) -> (B, D, L)
x_conv = x_emb.transpose(1, 2)
# 对每一层应用独立的卷积处理(此处简化为共用,若需每层独立可移动到循环内)
x_conv = self.layers[0].conv1d(x_conv)[:, :, :seq_len].transpose(1, 2)
all_layer0_outputs = []
pc_loss_sum = 0
for t in range(seq_len):
new_states = []
current_input = x_conv[:, t]
# 自底向上逐层传递
layer_outputs = []
for l in range(self.num_layers):
# 输入来自于上一层输出或嵌入层
h_in = current_input if l == 0 else layer_outputs[l-1]
# 传入上一时刻隐状态和来自高层的误差
out_l, h_t_l = self.layers[l](h_in, states[l], errors[l+1])
new_states.append(h_t_l)
layer_outputs.append(out_l)
# 计算预测编码损失 (自上而下)
step_pc_loss = 0
for l in range(self.num_layers - 1):
h_pred = self.layers[l].f_pred(layer_outputs[l+1])
error = layer_outputs[l] - h_pred
errors[l] = error.detach()
step_pc_loss += torch.mean(error**2)
pc_loss_sum += step_pc_loss
states = new_states
# 【关键注释】:原本输出的是网络最底层(Layer 0)的表征神经元数值 all_layer0_outputs.append(layer_outputs[0])
# 【必须】改成输出网络最高层的表征神经元数值
all_layer0_outputs.append(layer_outputs[-1])
return torch.stack(all_layer0_outputs, dim=1), states, pc_loss_sum / seq_len
class SSPCLanguageModel(nn.Module):
def __init__(self, vocab_size, model_dim, num_layers):
super().__init__()
# 1. 词嵌入:维度直接设为 model_dim,不再需要中间的全连接层
self.embedding = nn.Embedding(vocab_size, model_dim)
# 全连接层:确保输入与模型维度匹配并提供初始变换
# self.input_fc = nn.Linear(model_dim, model_dim)
self.sspc_core = SSPCModel(model_dim, num_layers)
# 词向量到词汇表的投影,共享权重以减少参数
self.lm_head = nn.Linear(model_dim, vocab_size)
self.lm_head.weight = self.embedding.weight # Weight Tying
def forward(self, input_ids, states=None, top_error_noise=None):
# 直接连接进 SSPC 层
x_emb = self.embedding(input_ids)
# 【关键注释】:注意核心计算后,返回的是基于哪一层表征的预测?
pred_vecs, next_states, pc_loss = self.sspc_core(x_emb, states, top_error_noise)
logits = self.lm_head(pred_vecs)
return logits, next_states, pc_loss
@torch.no_grad()
def generate(self, input_ids, max_new_tokens, temperature=1.0, top_k=50):
"""标准 T 生成算法"""
self.eval()
generated = input_ids
states = None
for _ in range(max_new_tokens):
logits, states, _ = self.forward(generated[:, -1:], states)
next_token_logits = logits[:, -1, :] / (temperature + 1e-8)
v, _ = torch.topk(next_token_logits, min(top_k, next_token_logits.size(-1)))
next_token_logits[next_token_logits < v[:, [-1]]] = -float('Inf')
probs = torch.softmax(next_token_logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
generated = torch.cat((generated, next_token), dim=1)
if next_token.item() == 3: break # [EOS]
return generated
@torch.no_grad()
def generate_bio(self, input_ids, max_new_tokens, noise_intensity=0.01, temperature=1.0):
"""
生物启发式生成算法:
在高于最高层的误差神经元 (errors[num_layers]) 注入噪声来指导生成。
"""
self.eval()
generated = input_ids
states = None
device = input_ids.device
for _ in range(max_new_tokens):
# 生成一束针对最高层误差神经元的微弱噪声
# 这个噪声通过 down_weight 逐层向下渗透,影响最底层的输出
noise = torch.randn(input_ids.size(0), self.sspc_core.model_dim).to(device) * noise_intensity
logits, states, _ = self.forward(generated[:, -1:], states, top_error_noise=noise)
# 此处仍需基础采样以获得具体的 token,但分布已被顶层噪声“扰动”
next_token_logits = logits[:, -1, :] / (temperature + 1e-8)
probs = torch.softmax(next_token_logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
generated = torch.cat((generated, next_token), dim=1)
if next_token.item() == 3: break
return generated